In this blog post, you will get to know ClickHouse, a high-performance column-oriented database that plays a critical role in modern data architectures. It is especially valuable for organizations that need to process and analyze large volumes of data in real time, with millisecond-level latency and efficient resource usage.
Whether you’re building internal analytics tools, serving customer-facing dashboards, or running complex event-based pipelines, understanding ClickHouse can be a key differentiator for your data stack.
ClickHouse is designed to answer one fundamental challenge: how to analyze billions of rows of data quickly, efficiently, and cost-effectively. With its unique approach to columnar storage and execution, it stands out as one of the fastest and most scalable solutions in the open-source analytics ecosystem.

This article will guide you through:
What ClickHouse is and how it works at a low level
The architecture that makes it so fast
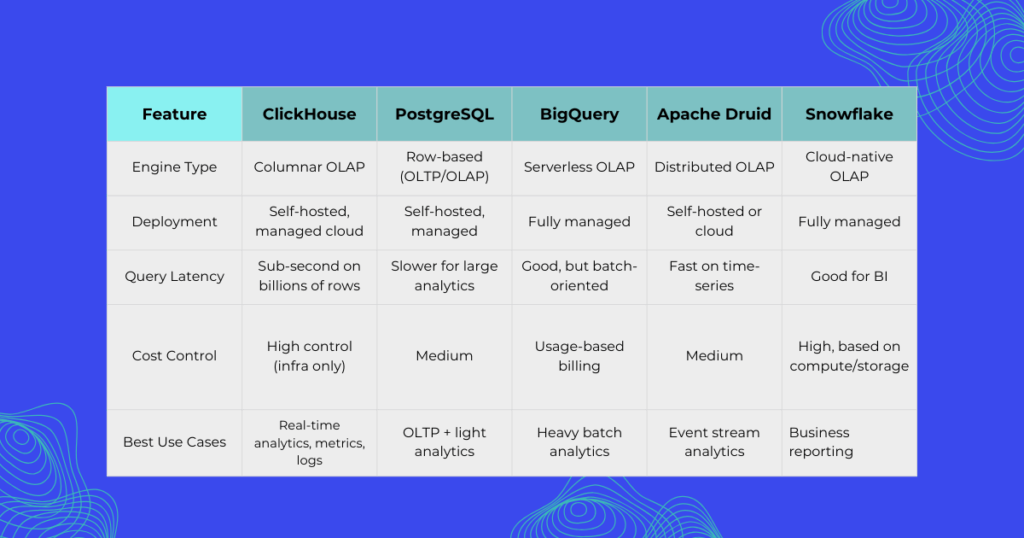
Comparisons with other analytical databases like PostgreSQL, BigQuery, Druid, and Snowflake
Practical use cases and real-world deployment scenarios
Example schemas and queries optimized for performance
Common pitfalls and when not to use ClickHouse
Best practices for tuning and running ClickHouse in production
Let’s dive deep into the internals and understand why ClickHouse has become a foundational component for companies that take data seriously.
ClickHouse stands out as a high-performance, cost-effective, and scalable solution for real-time analytics. It combines the speed of columnar storage with a flexible SQL interface and production-grade reliability.
If your use case involves querying billions of rows, serving data-heavy dashboards, or analyzing event streams in real time, ClickHouse is one of the most capable tools available today.
Its open-source nature, active community, and growing ecosystem make it a strong candidate for modern data architectures. With proper design and tuning, it can deliver query latencies measured in milliseconds, on data volumes measured in terabytes.
Looking to evaluate ClickHouse for your organization? Start with a small proof of concept using your real data and focus on query design, partitioning strategy, and storage configuration. The performance benefits will be evident from the first test!








