OCR is the process of transforming visual representations of text, such as those found in images or scanned files, into digital characters that can be stored, searched, edited, and processed programmatically.

The process typically involves the following technical stages:
1. Image Preprocessing
Before recognition, images are enhanced to improve readability. This step may involve grayscale conversion, noise reduction, skew correction, binarization, and contrast normalization.
2. Layout Analysis
The system detects and segments the content into logical components such as text blocks, lines, tables, and images. This is critical for preserving the structure of complex documents.
3. Character Recognition
OCR engines use pattern recognition, convolutional neural networks (CNNs), and natural language processing (NLP) to detect and classify characters. Some systems also support multiple languages, font styles, and handwritten text.
4. Post-processing and Validation
The recognized text is cleaned, validated, and structured. AI-based models use contextual clues and dictionaries to correct errors and format data into standardized outputs such as JSON, XML, or CSV.
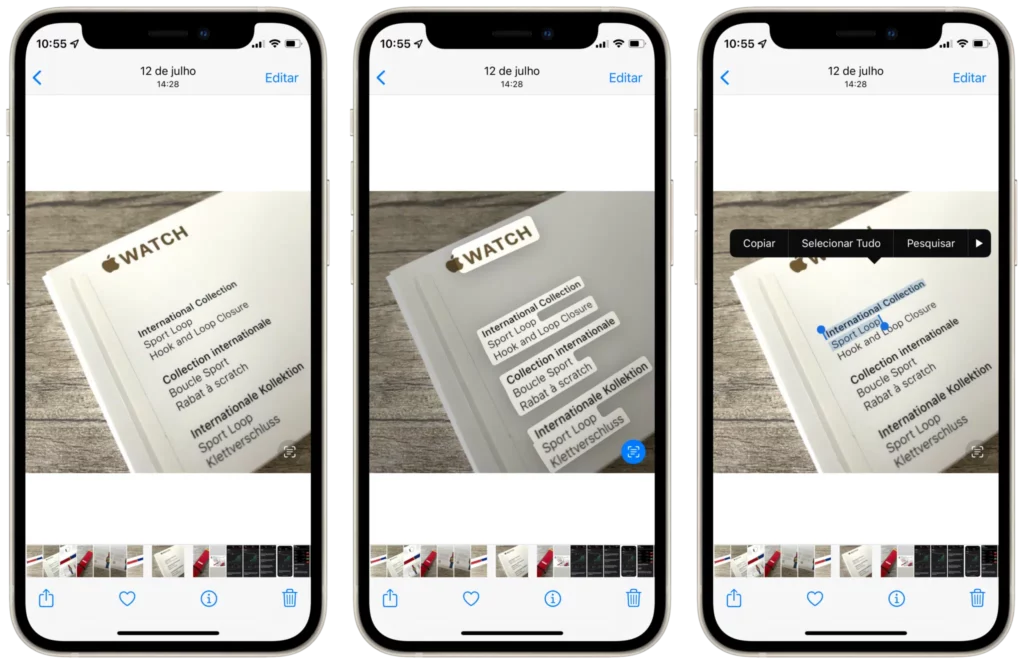
Parser enables organizations to automate data extraction, reduce processing times, and increase accuracy across all document types. With advanced AI, fast setup, and robust integration options, it is an ideal solution for teams looking to scale document processing without expanding operational overhead.
Visit Parser to create your account and start automating your workflow with 10 free credits. No credit card required.








