Have you ever struggled to interpret the decisions of an AI? SHAP was created to help you overcome these issues. The acronym stands for SHapley Additive exPlanations, a relatively recent method (less than 10 years old) that seeks to explain the decisions of artificial intelligence models in a more direct and intuitive way, avoiding “black box” solutions.
Its concept is based on game theory with robust mathematics. However, a complete understanding of the mathematical aspects is not necessary to use this methodology in our daily lives. For those who wish to delve deeper into the theory, I recommend reading this publication in English.
In this text, I will demonstrate practical interpretations of SHAP, as well as understanding its results. Without further ado, let’s get started! To do this, we’ll need a model to interpret, right?

I will use as a basis the model built in my notebook (indicated by the previous link). It is a tree-based model for binary prediction of Diabetes. In other words, the model predicts people who have this pathology. For the construction of this analysis, the shap library was used, initially maintained by the author of the article that originated the method, and now by a vast community.
First, let’s calculate the SHAP values following the package tutorials:

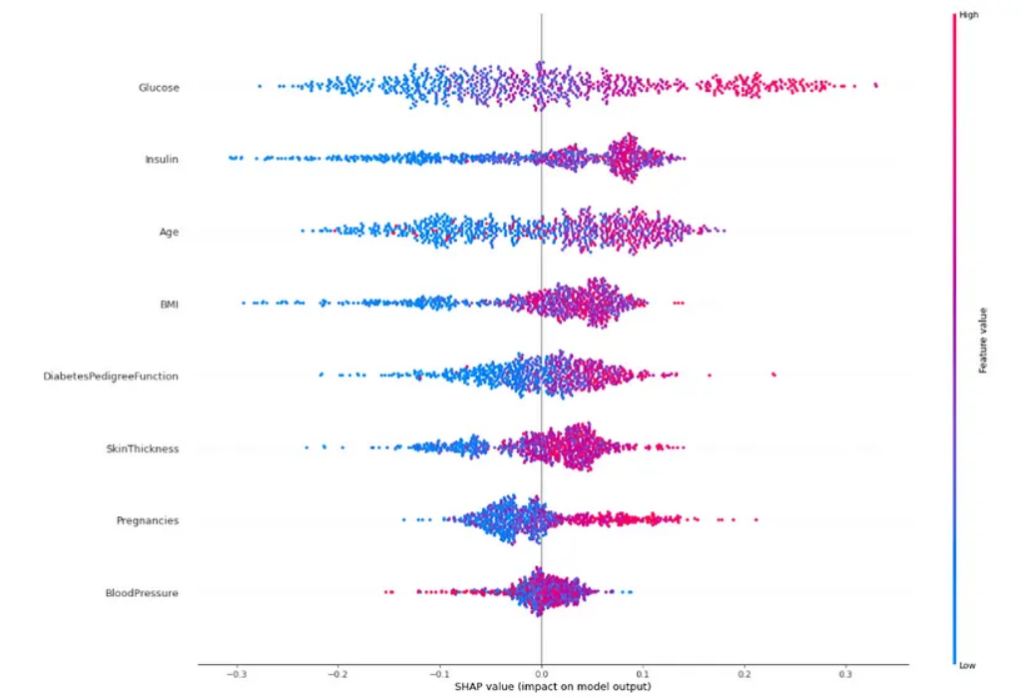
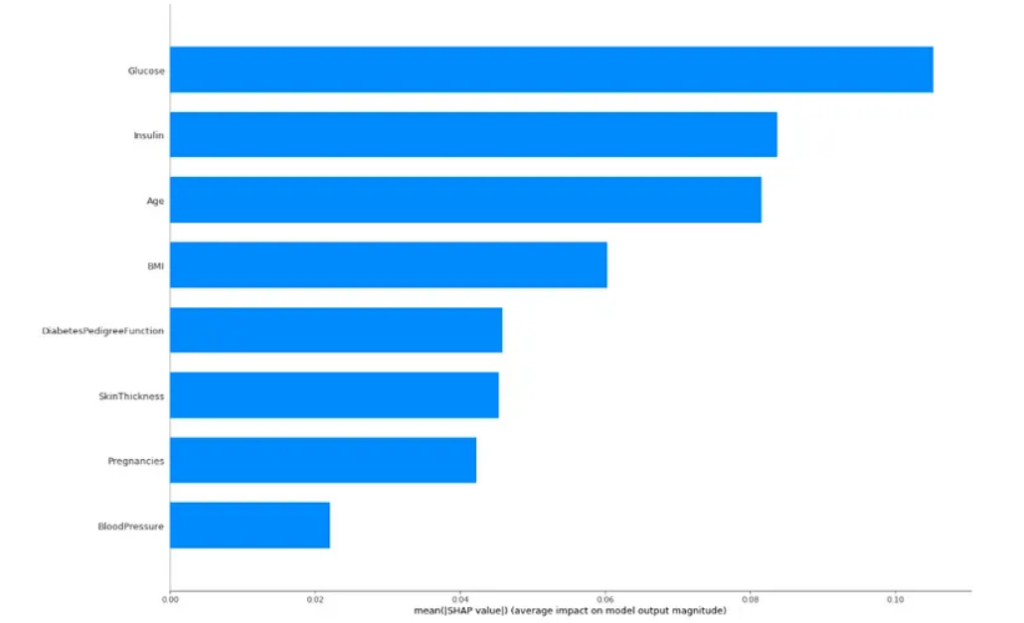
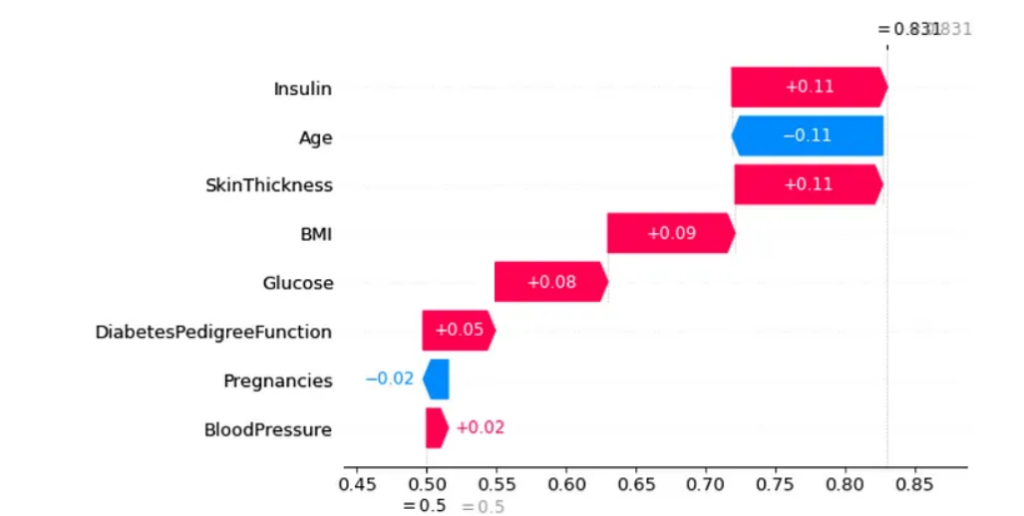
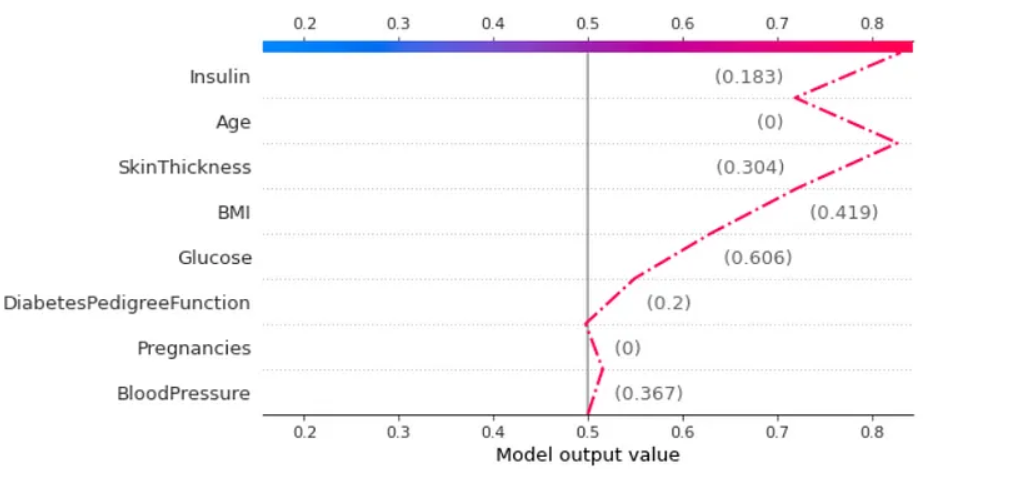
SHAP emerges as a tool capable of explaining, in a graphical and intuitive way, how artificial intelligence models arrive at their results. Through the interpretation of the graphs, it is possible to understand the decision-making in Machine Learning in a simplified manner, allowing for explanations to be presented and knowledge to be conveyed to people who do not necessarily work in this area.
Throughout this text, we were able to assess the key concepts about SHAP values, as well as their visualizations. From SHAP values, we understand how the values of each variable influenced the model’s outcome. In this case, we evaluated the results in terms of probability. Analyzing the visualizations, it was possible to perceive that SHAP allows us to interpret specific and individual results, as well as understand what the scheme expresses about the problem.
Despite the robust mathematics, understanding this methodology is simpler than it seems. The SHAP technology does not stop here! There are many things that can be done with this technique, and that’s why I strongly recommend:
Do you want to discuss other applications of SHAP? Do you want to implement data science and make decision-making more accurate in your business? Get in touch with us! Let’s schedule a chat to discuss how technology can help your company!
Written by Kaike Reis.