Convolutional Neural Networks (CNNs) are a cornerstone of modern image analysis, drawing inspiration from the way the human brain processes visual data. By leveraging layers of interconnected nodes, CNNs excel at identifying patterns, features, and structures within images. This capability enables them to perform complex tasks such as facial recognition, object classification, image segmentation, and even medical imaging analysis with remarkable accuracy.
The power of CNNs lies in their hierarchical structure, which processes images in multiple stages. Early layers detect simple features like edges and colors, while deeper layers combine these features to identify complex shapes and objects. This layered approach makes CNNs particularly effective for large datasets, as they can generalize patterns efficiently. Their versatility has also extended beyond image processing, finding applications in natural language processing, video analysis, autonomous vehicles, and even generating realistic images through deep learning techniques.
What is a Convolutional Neural Network?
A Convolutional Neural Network (CNN) is a specialized type of deep neural network tailored to process and analyze unstructured data, particularly images and visual information. What sets CNNs apart is their unique architecture, which mimics the way the human brain interprets visual stimuli, allowing the network to automatically and adaptively learn spatial hierarchies of features. This ability to extract intricate patterns and structures from raw data makes CNNs a cornerstone of modern artificial intelligence, especially in the domain of computer vision.

These networks are highly efficient at identifying complex patterns in visual data, enabling them to excel in a wide array of tasks, such as image recognition, object detection, and semantic segmentation. By leveraging convolutional layers, CNNs scan images piece by piece, preserving spatial relationships while reducing computational overhead. This approach is ideal for large-scale datasets where precision and scalability are essential. Beyond traditional image analysis, CNNs have also been applied to video processing, medical imaging, and even domains like natural language processing and generative art, showcasing their versatility in addressing diverse challenges.
CNN Architecture
A CNN is composed of several layers, each serving a specific purpose. The main components include the input layer, convolutional layers, pooling layers, and fully connected layers.
- The convolutional layers use filters to extract features like edges or textures from the input image.
- The pooling layers reduce the spatial dimensions of the data, minimizing computational costs while preserving essential information.
- Finally, the fully connected layers take the extracted features and produce the final prediction.
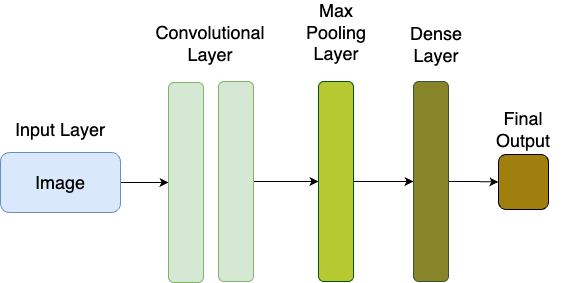
Basic Architecture for CNNs (source).
The network adjusts its filters and connections during training through backpropagation, a method that calculates the error by comparing predictions to the actual output and distributes this error backward through the layers. Using gradient descent, the network updates the weights to minimize the error and improve accuracy. Although these techniques are fundamental to neural networks in general, they are also key to understanding how CNNs operate. Next, we’ll explain the specific functioning of CNNs in detail.
How CNNs Work?
Convolutional Neural Networks (CNNs) operate using convolutional layers that apply filters, also known as kernels, to input images. These filters act as pattern detectors, extracting relevant features such as edges, textures, and shapes from the raw pixel data. Each filter is designed to identify a specific characteristic of the image, such as horizontal lines or circular patterns, and the process involves scanning the image piece by piece to ensure spatial relationships are preserved.
As data flows through the layers, the network progressively combines these extracted features to build a more complete and nuanced understanding of the image. Early layers focus on detecting simple structures like edges and corners, while deeper layers identify more complex features, such as objects, faces, or scenes. This hierarchical feature extraction process allows CNNs to generalize and recognize patterns even in noisy or varied datasets. The pooling layers, often interspersed between convolutional layers, further refine the network by reducing spatial dimensions and emphasizing the most critical features, improving efficiency without sacrificing accuracy.
Convolutional Layers
The convolutional layer is the core building block of a Convolutional Neural Network (CNN) and is where most of the feature extraction occurs. This layer is designed to mimic the way the human visual cortex processes images, breaking down visual data into smaller, meaningful parts that can be analyzed.
1. Filters or Kernels: At the heart of the convolutional layer are filters (also known as kernels), which are small matrices (e.g., 3×3, 5×5, or 7×7). These filters are applied across the input image in a sliding-window fashion, performing convolution operations.
- Each filter is trained to detect specific features, such as edges, corners, textures, or other patterns in the image.
- Filters are initialized with random weights, which are later adjusted during training to optimize feature detection for a given task.
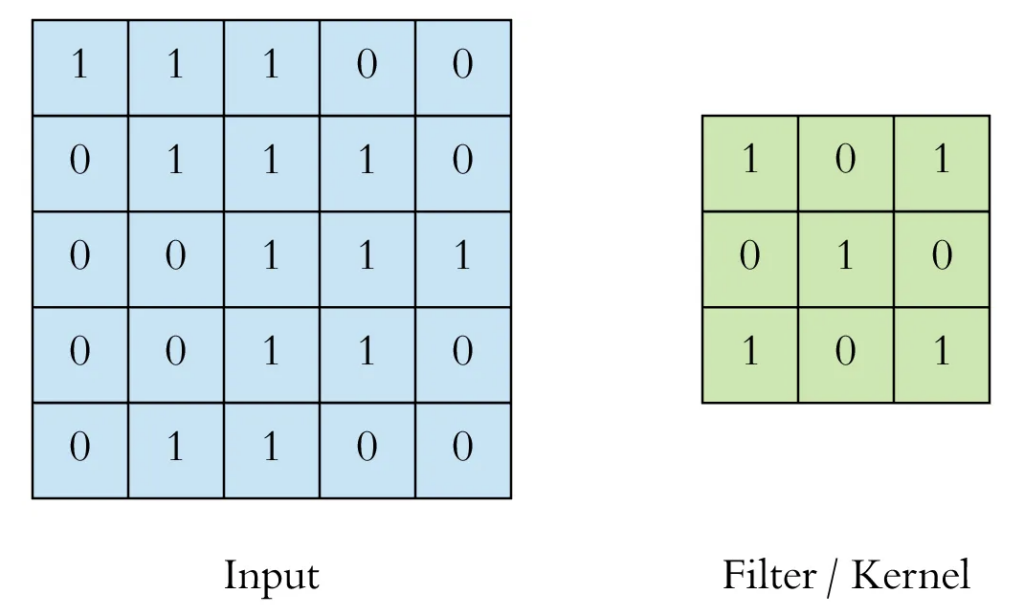
Representation of an image matrix input next to a filter to be applied on it (source).
2. Feature Maps: When filters are applied to the input image, they generate feature maps, which are the main outputs of a convolutional layer. These maps represent different aspects of the input image, capturing localized features identified by each filter.
- The size of the feature map depends on the size of the filter, the stride, and whether padding is applied.
- The intensity of the values in the feature map corresponds to how strongly a feature is present in a specific region of the input image.
- The output of the convolution operation is a transformed version of the input image, emphasizing the detected features, which is known as a feature map.
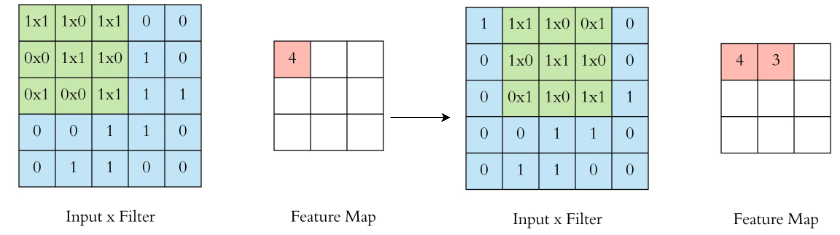
Feature Maps representation (source).
3. Key Characteristics of Convolutional Layers
- Local Connectivity: Each filter focuses on a small region of the image, allowing the network to detect local patterns without considering the entire image at once.
- Weight Sharing: The same filter is applied across the entire image, reducing the number of parameters and making the model more efficient.
- Parameter Optimization: Filters are not pre-defined but are learned during training to optimize feature extraction for the task at hand.
Pooling Layers
Pooling layers are an essential component of CNNs, used to downsample feature maps after they are generated by convolutional layers. By reducing the spatial dimensions of feature maps, pooling layers help decrease computational complexity, making the network more efficient and less prone to overfitting.
The primary function of pooling layers is to condense the information in a feature map while preserving the most important features, ensuring that the subsequent layers process only the essential data.
How Pooling Works
Pooling layers divide the feature map into smaller non-overlapping regions (e.g., 2×2 or 3×3 regions) and perform a specific operation on each region to reduce its size. The result is a downsampled feature map with fewer dimensions but containing the most relevant information.
Pooling is a local operation, meaning it processes each small region of the feature map independently. This allows the network to retain the most significant aspects of the data while discarding redundant or less important details.
Types of Pooling
1. Max Pooling:
- Max pooling selects the maximum value within each pooling region.
- This operation highlights the most prominent features in the feature map, making it useful for tasks that require identifying strong activations, such as edges or corners.
- Max pooling tends to preserve sharp, distinct features, making it the most commonly used pooling method in CNNs.
2. Average Pooling:
- Average pooling calculates the average value of all elements within the pooling region.
- It provides a smoother representation of the feature map and is often used when retaining a more generalized understanding of the features is required.
- While less common in modern CNN architectures, average pooling can be useful in applications where smooth gradients are preferred, such as feature extraction for pre-trained models.
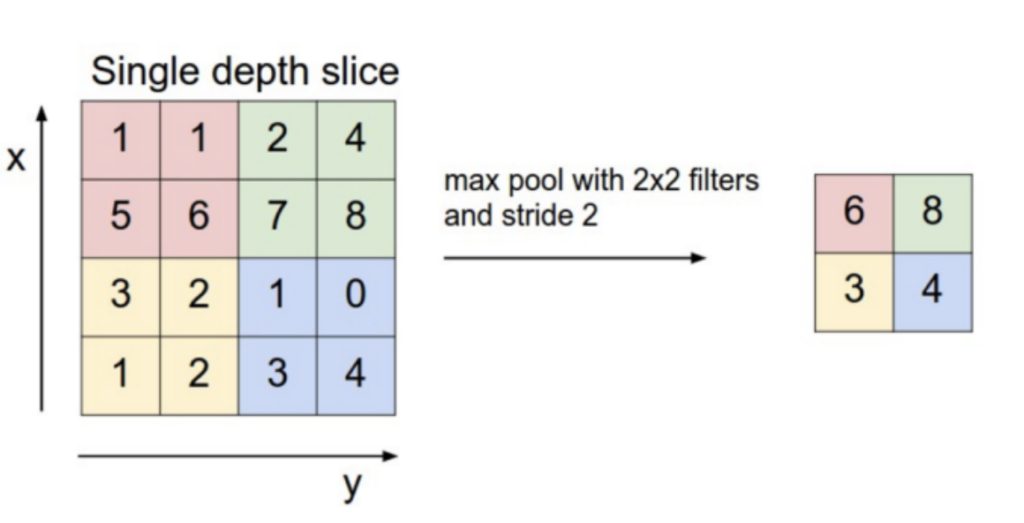
Graphic representation of Max Pooling with a kernel 2×2. In the input, we can see that the greater number in the red zone is 6, so in the kernel we have 6 in the red zone (source).
Hierarchy of Features
CNNs operate hierarchically, progressively analyzing an input image in stages, starting with basic elements and advancing toward increasingly complex patterns. In the initial layers, the network focuses on identifying simple features such as edges, corners, and textures. These fundamental building blocks are essential for understanding more intricate structures and provide the foundation for deeper analysis. By examining the image in small, localized regions, CNNs ensure that spatial relationships are preserved, which is crucial for tasks like object recognition and scene interpretation.
As the image data moves deeper into the network, the layers begin to detect more sophisticated features, such as shapes, contours, and eventually complete objects. This structured approach allows CNNs to build a deep, layered understanding of the image, with each stage refining and expanding on the information extracted in the previous one. The hierarchical nature of CNNs not only enhances their ability to recognize patterns across a wide range of scales but also makes them robust to variations in lighting, orientation, and other factors. This scalability and precision make CNNs indispensable for applications like facial recognition, medical imaging, and autonomous systems, where accuracy and detail are paramount.
Early Layers: Detecting Basic Features
The first layers of a CNN focus on extracting low-level features from the input image. These features are fundamental building blocks of visual information and include:
- Edges: Horizontal, vertical, and diagonal lines.
- Corners: Points where multiple edges meet.
- Textures: Simple patterns or gradients that describe surface details.
At this stage, the filters or kernels are relatively simple and sensitive to changes in pixel intensity over small regions. For example:
- A kernel might detect a sudden change in intensity, indicating the presence of an edge.
- Another might identify repetitive patterns, highlighting textures.
These features are generic and not specific to any particular object, meaning they could apply equally to an image of a cat, a car, or a tree.
Intermediate Layers: Detecting Patterns and Shapes
As the data passes through subsequent layers, the network begins to combine the low-level features detected in earlier layers into mid-level patterns.
- These patterns might include combinations of edges to form contours, shapes, or geometric structures.
- For example:
- An edge might combine with other edges to form a rectangle or a circle.
- A texture might evolve into a specific material, such as fur or metal.
At this stage, the features are more specific but still not fully object-specific. They represent common patterns that could be part of many objects.
Deeper Layers: Detecting Complex and Abstract Features
In the final layers of the CNN, the network begins to combine mid-level features into high-level, object-specific representations.
- These layers identify complex patterns, such as the shape of a face, the silhouette of a car, or the texture of an animal’s fur.
- The features at this stage are abstract and provide a holistic understanding of the object in the image.
For instance:
- In an image of a dog, the deeper layers might combine edges (detected earlier) into the shape of a head, and textures into details like fur color or nose structure.
This progressive abstraction is what makes CNNs so powerful for tasks like object recognition and image classification. Each layer contributes a different level of understanding, building on the features detected in previous layers.

Representation of the hierarchy of features. The top shows deeper layers (high-level features), the middle represents intermediate layers, and the bottom shows early layers (basic features) (source).
Hyperparameters in Convolutional Layers
The behavior and performance of a convolutional layer in a CNN are significantly influenced by key hyperparameters. These hyperparameters determine how the filters interact with the input image, how much information is retained, and the resolution of the resulting feature maps. Understanding these parameters is crucial for designing efficient and effective models.
Key Hyperparameters
1. Filter Size:
- The filter size defines the dimensions of the kernel used in the convolution operation.
- Smaller filters are commonly used in modern CNNs because they are computationally efficient and capture fine-grained details.
- Larger filters may capture a broader context but are more computationally expensive and can blur fine details.
- Larger filters extract more global features, while smaller filters focus on local patterns, such as edges and textures.
2. Stride:
- The stride specifies how far the filter moves across the input image during the convolution operation.
- A stride of 1 ensures that every pixel is covered, leading to higher-resolution feature maps.
- A stride of 2 skips pixels, reducing the spatial dimensions of the feature maps and speeding up computation.
- Larger strides produce smaller feature maps but reduce the computational load. Smaller strides retain more spatial details.
3. Padding:
- The padding adds artificial borders to the input image to maintain its original spatial dimensions after convolution.
- Types of padding:
- Same padding: Ensures that the output dimensions are the same as the input dimensions by adding enough borders.
- Valid padding: No padding is applied, resulting in smaller feature maps after convolution.
- Padding helps preserve edge information in the image, especially when using small filters.
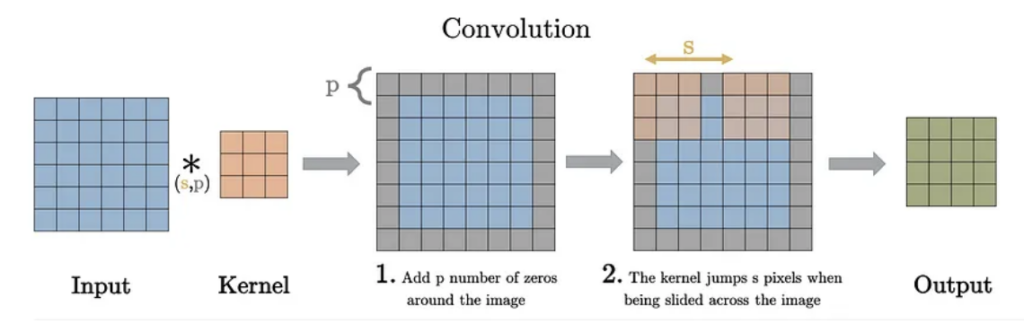
How hyperparameters work in Convolutional Layers. The p stands for padding and s for stride (source).
Final Classification with Fully Connected Layers
After the convolutional and pooling layers have extracted and condensed the image features, the data is passed to one or more fully connected layers (also called dense layers). These layers serve as the “decision-making” part of the CNN.
1. Feature Flattening:
- The multidimensional output from the final pooling layer is flattened into a one-dimensional vector, making it suitable for fully connected layers. For example:
- A 3x3x128 feature map is converted into a 1D vector of 1152 elements.
2. Learning High-Level Relationships:
- Fully connected layers connect every input neuron to every output neuron, learning global patterns in the extracted features.
- By assigning weights to these connections, the network combines features to produce meaningful predictions.
3. Output Layer:
- The final fully connected layer contains as many neurons as the number of output classes or predictions.
- For classification tasks, this layer applies an activation function (e.g., softmax) to assign probabilities to each class.
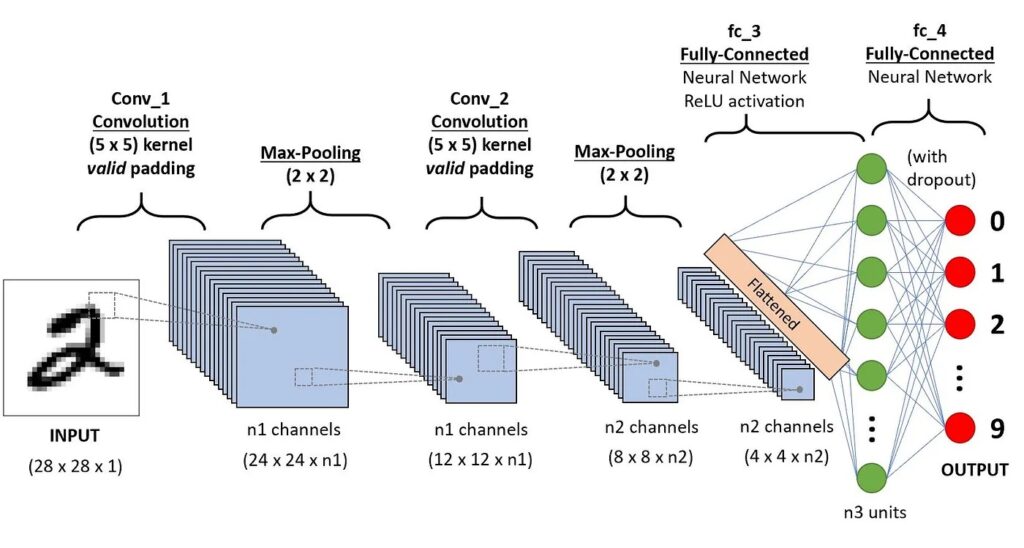
A sequence to classify handwritten digits (source).
Applications of Convolutional Neural Networks
CNNs are highly adaptable and have been very useful in numerous fields due to their ability to process visual data effectively. Below are some prominent applications:
- Image Recognition: CNNs classify images by detecting specific objects (e.g., cats, dogs) and are widely used in search engines and social media platforms for content tagging.
- Object Detection: These networks locate and identify objects within an image, making them indispensable in applications like autonomous driving and surveillance systems.
- Facial Recognition: CNNs power facial recognition systems used for security, authentication, and even social media tagging, identifying individuals with high precision.
- Medical Diagnosis: In healthcare, CNNs analyze medical images such as X-rays, CT scans, and MRIs, assisting doctors in diagnosing diseases early and accurately.
Wrapping things up
Convolutional Neural Networks (CNNs) are transformative tools in the field of computer vision, offering unmatched capabilities in recognizing patterns, identifying objects, and analyzing complex visual data. By mimicking the way our brains process visual information, CNNs have revolutionized applications ranging from facial recognition to medical diagnostics, proving their value across diverse industries. Whether you’re exploring ways to improve image classification or seeking to apply CNNs to solve real-world problems, understanding their architecture and operation is essential.
Ready to discover how CNNs can enhance your projects or business strategies? Click the banner below to connect with our specialists and learn how this cutting-edge technology can work for you!






