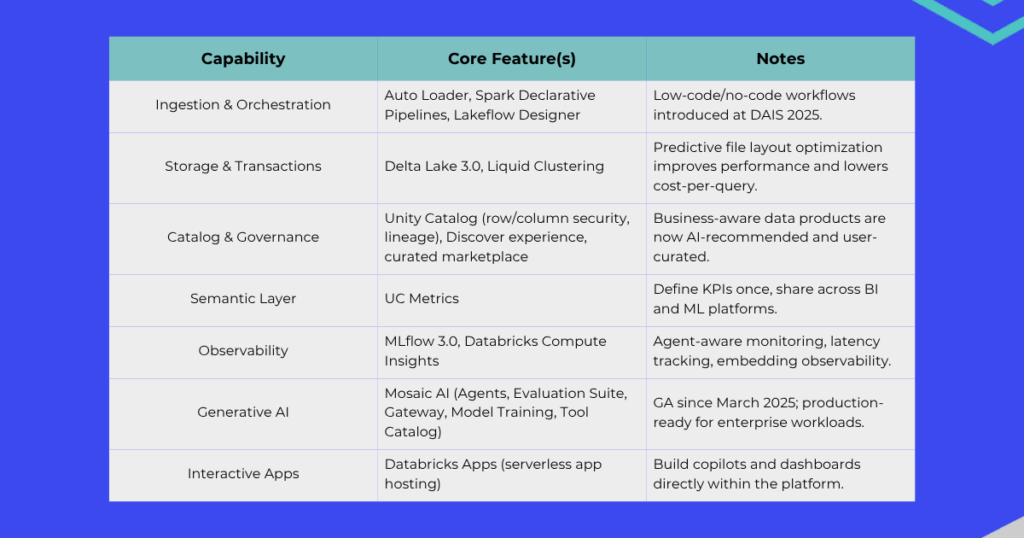
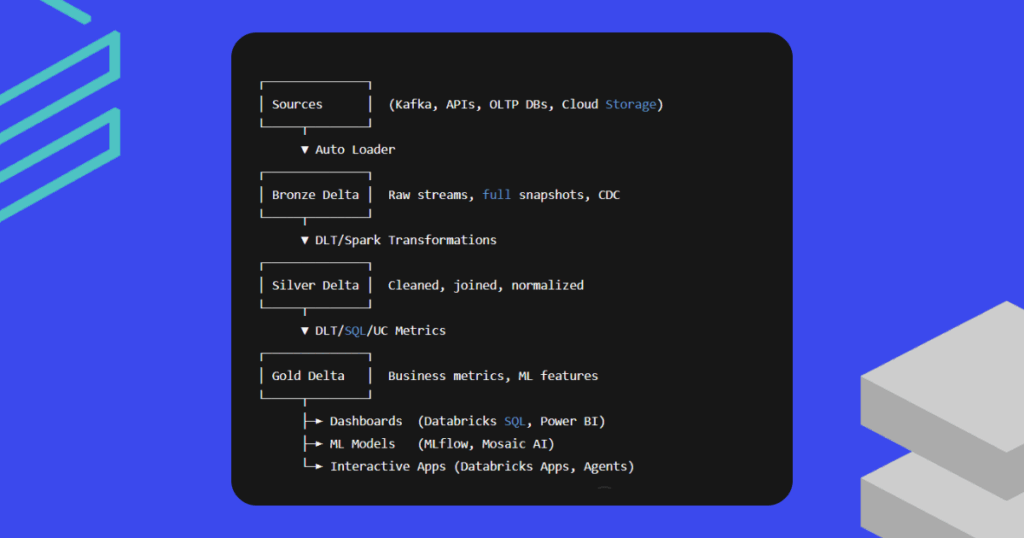
Databricks has evolved well beyond “a platform to run Spark.” It now delivers vertically integrated capabilities across the entire data lifecycle: from data ingestion and storage to processing, analytics, machine learning, and governance. Its native Delta Lake technology ensures data reliability with ACID transactions and version control, making it easy to manage large, complex datasets in cloud environments.

Is Databricks only for big enterprises?
Not at all. Many lean teams operate entirely on a single workspace with serverless SQL and still build high-impact solutions. Its modular structure allows you to start small and scale when ready.
What skills do I need to use Databricks effectively?
Basic SQL is more than enough to get started. Python is helpful for transformations and machine learning, but Spark complexity is abstracted away by tools like Databricks SQL and Delta Live Tables.
Can I run GenAI apps in production on Databricks?
Absolutely. Mosaic AI delivers all the necessary components: vector storage, embedding, orchestration, guardrails, evaluation tools, and production-ready hosting.
What if I already use Snowflake or BigQuery?
You don’t need to migrate everything. Databricks’ data federation lets you query Snowflake, BigQuery, Oracle, and Iceberg natively. You only move what’s necessary.
How secure is Unity Catalog?
Unity Catalog enables layered governance with workspace isolation, RBAC, ABAC, column masking, row filtering, and detailed audit logs. It integrates with enterprise identity providers like Okta and Azure AD.
Is Databricks meant to replace my BI tool?
No. It can serve as your full-stack analytics engine, but it also integrates seamlessly with Tableau, Power BI, Looker, and other tools. Databricks SQL provides robust dashboarding without forcing a migration.
Whether you’re solving a single use case or replacing an outdated legacy platform, the key to success with Databricks is designing with scale and governance in mind from the start.
Our team has helped clients ranging from startups to large enterprises unlock the full value of Databricks. We support data warehouse migrations, real-time analytics, MLOps pipelines, and AI co-pilots in production.
If you’re evaluating Databricks or just want a second opinion on your current setup, we’re here to help.
Click the banner bellow and let’s talk today!








